証券投資(現代ポートフォリオ理論)をコンパクトに学ぶべく、比較的最近に発刊され薄めの本である
")
を参考に学んでいく。
- 前回:
3. ポートフォリオ理論
3.7. 無リスク資産を含むポートフォリオ
無リスク証券が存在するとして、無リスク資産を組み入れたポートフォリオを考える。このときの最適ポートフォリオとして
が得られる。
これを代入することでポートフォリオの分散は
である。すなわち平面では放物線を描き、
平面では
軸上の切片を
とした傾き
の半直線を描く。
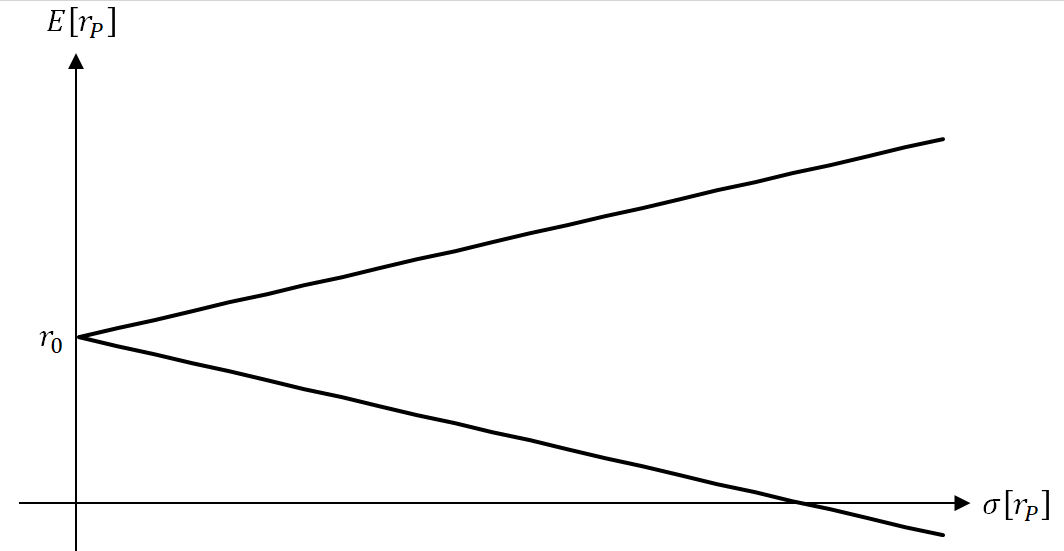
すなわち
である。
リスク証券からのみ構成されるポートフォリオと同様に効率的ポートフォリオは点を切片とした傾き
を持つ半直線からなる。
無リスク証券を含む効率的ポートフォリオおよびリスク証券のみからなる効率的ポートフォリオとを組み合わせたときにどのような議論が成り立つか。
リスク証券のみからなる効率的ポートフォリオは双曲線であり、特に
である場合、
となり、半直線はリスク証券のみからなる効率的ポートフォリオの漸近線になる。
このとき最適ポートフォリオは
となるから、となり、最適ポートフォリオは無リスク証券への集中投資である。
リスク証券への投資比率の合計はであるから、これは自己資産
でポートフォリオを形成するという意味で最低ポートフォリオを保有することを意味する。
以上の考察をまとめる:
無リスク証券を含むポートフォリオ 無リスク証券およびリスク証券からなるポートフォリオにおいて
この命題から、接点ポートフォリオが存在する場合、任意の効率的ポートフォリオは接点ポートフォリオおよび無リスク証券の一次結合で表現できるから、効率的ポートフォリオおよび接点ポートフォリオは完全相関の関係にある。
接点ポートフォリオおよび無リスク証券からなる効率的ポートフォリオのリスク・リターン 無リスク証券があるとき、任意の効率的ポートフォリオを
を満たす。
である。このとき
を踏まえると、あるポートフォリオの各リスク証券との共分散ベクトルを
とすれば
である。接点ポートフォリオは
であるから、これを代入して
を得る。これをについて解くことで
を得る。
一方で効率的ポートフォリオのリターンの分散は、
を踏まえれば、
である。を代入して
を得る。の第
番目の要素は
に等しいから、示すべき式を得る。
)
この命題は、資本資産評価モデル(CAPM)が平均=分散モデルに依拠していることを示唆している。
3.8 平均=分散モデルの問題点
平均=分散モデルはリスク尺度として分散(標準偏差)を採用しており、効用関数が2次関数であるかリターンが正規分布に従うならば、平均=分散モデルは期待効用最大化と整合的になる。しかしこうした仮定はかなり強い者であり、批判もある。
- 証券の数が増大すると分散共分散行列の逆行列を計算し難くなる。
- 平均=分散モデルは、効用関数を2次関数と仮定するかリターンが正規分布に従うという強い仮定を置かない限り、期待効用最大化と整合性が取れない。
- 平均=分散モデルでのリスク尺度である標準偏差は期待リターンを上回るリターンもリスクと見なしてしまい、不自然である。
- 平均=分散モデルは3次以上の高次モーメントを反映しない。
- 次回: