以下の書籍

を中心に時系列解析を勉強していきます。
前回
15. 一般状態空間モデルの一括解法
15.1 MCMC
これまで議論してきた線形・型状態空間モデルは解を解析的に導出できた。しかし一般的な状態空間モデルでは基本的に解析的な解の導出は不可能である。計算機能力が上がってきた現在では、数値的に解を導出するのが一般的になってきた。その手法の1つに
連鎖
法(
)を用いる方法がある。
15.2 MCMCによる状態の推定
を活用した平滑化では、推定対象の分布を同時事後分布
として扱うのが一般的である。更に母数を確率変数として捉える場合、同時事後分布は
となる。
を活用して同時事後分布から標本を得る方法を考える。ここでは
法によるサンプリングを考える。
- 1. 初期値
を準備する。
- 2.
に対して a.
から
をサンプリングする。 b.
から
をサンプリングする。
- 3.
を
からの標本とする。
ここでは
連鎖の計算における総繰り返し回数であり、ある繰り返し
における変数の実現値を
と表す。
もし線形・型状態空間モデルを用いる場合、前向きフィルタ後ろ向きサンプリング(
)と呼ばれる特別に効率の良いアルゴリズムが存在する。
- 1. 母数を
としてカルマン・フィルタリングを行なう。
- 2.
から
をサンプリングする。
- 3.
に対して a. 平滑化利得
とする。 b.
から
をサンプリングする。ここで
である。
15.3 ライブラリの活用
で状態空間モデルを活用するパッケージに
や
がある。
一方で外部ソフトウェアにはや
がある。
15.3.1 例:人工的なローカルレベルモデル
ここではや
の使い方に習熟すべく、人工データを基にシミュレーションを行なってみる。
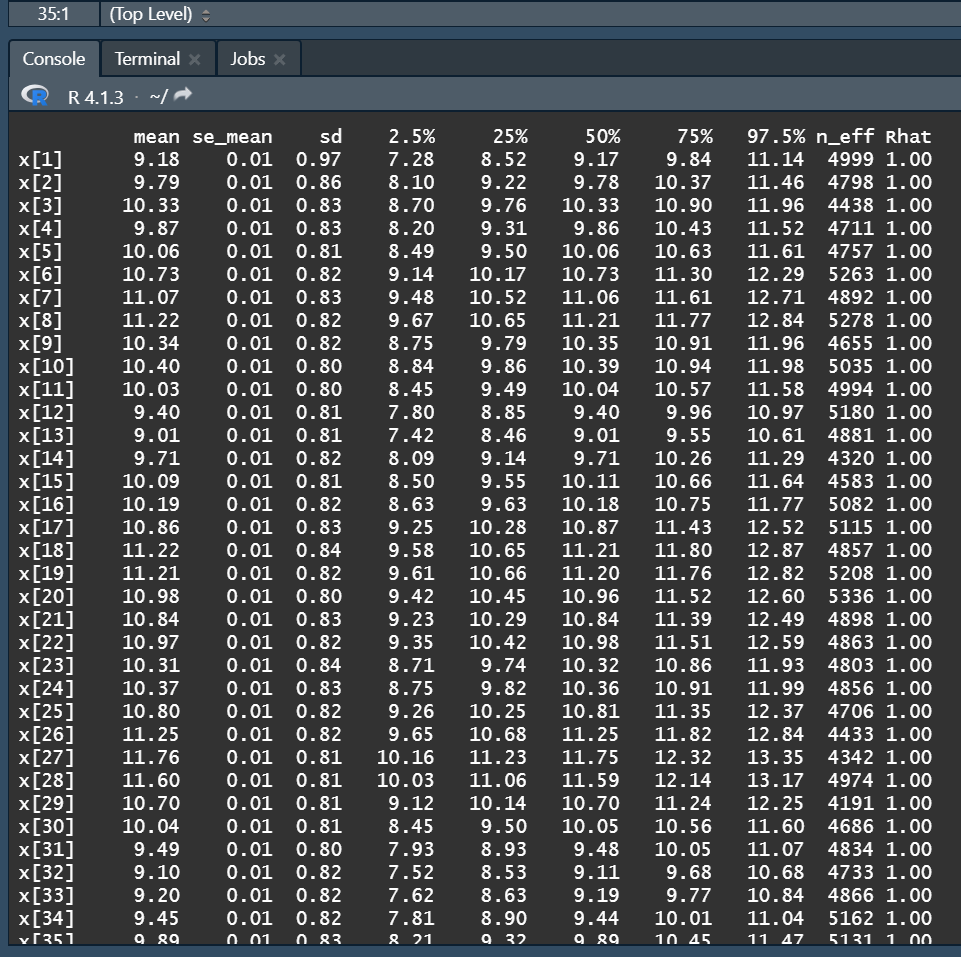
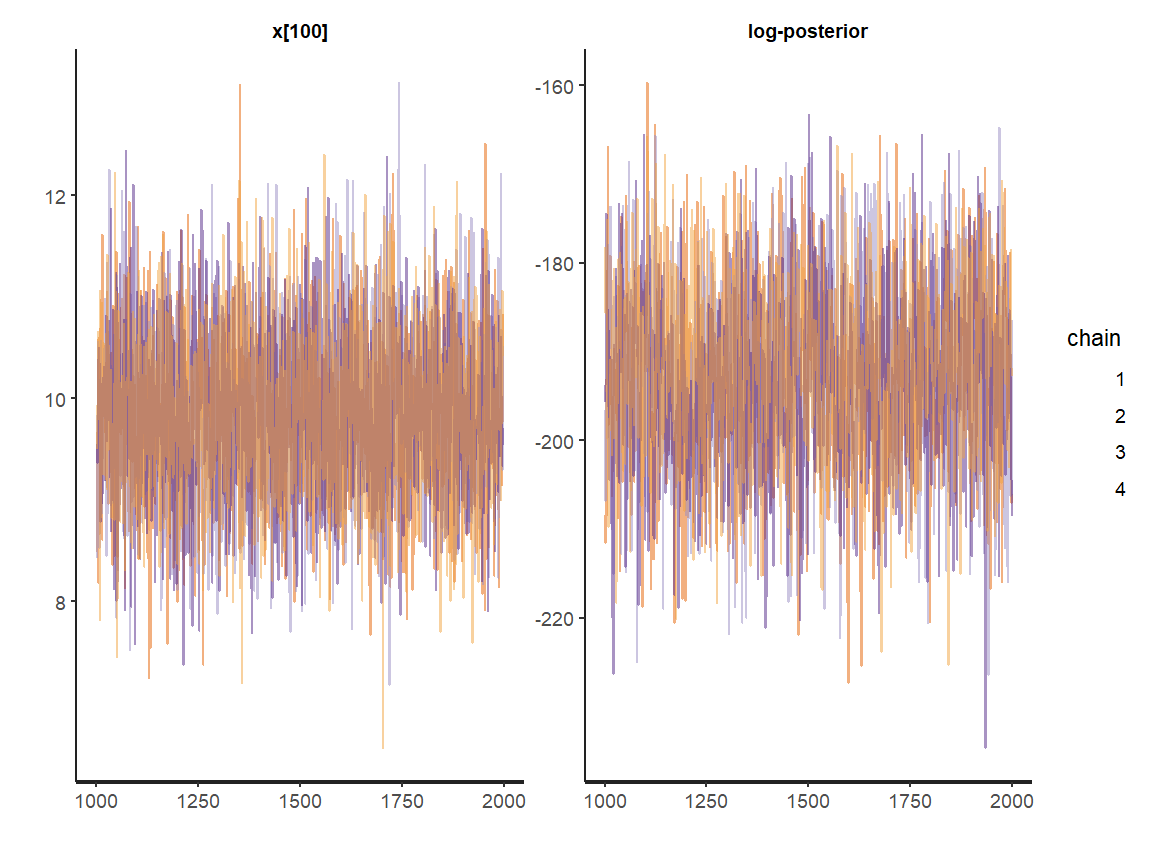
set.seed(123) library(rstan) # 人工データの生成 library(dlm) W <- 1 V <- 2 m0 <- 10 C0 <- 9 mod <- dlmModPoly(order = 1, dW = W, dV = V, m0 = m0, C0 = C0) t_max <- 200 sim_data <- dlmForecast(mod = mod, nAhead = t_max, sampleNew = 1) y <- sim_data$newObs[[1]] # Stanの利用準備 rstan_options(auto_write = T) options(mc.cores = parallel::detectCores()) theme_set(theme_get() + theme(aspect.ratio = 3/4)) stan_mod_out <- stan_model(file = ".../model10_1.stan") fit_stan <- sampling(object = stan_mod_out, data = list(t_max = t_max, y = y[,1], W = mod$W, V = mod$V, m0 = mod$m0, C0 = mod$C0), pars = c("x"), seed = 123) oldpar <- par(no.readonly = T) options(max.print = 99999) fit_stan options(oldpar) traceplot(fit_stan, pars = c(sprintf("x[%d]", 100), "lp__"), alpha = 0.5) stan_mcmc_out <- rstan::extract(fit_stan, pars = "x") str(stan_mcmc_out) s_mcmc <- colMeans(stan_mcmc_out$x) s_mcmc_quant <- apply(stan_mcmc_out$x, 2, FUN = quantile, probs = c(0.25, 0.75))
15.3.2 収束の判断
収束しているか否かは、主に3つの観点から調べる。
まずはトレースプロットによる目視である。トレースプロットは、横軸に試行の実行回数(何番目の試行か)、縦軸にその試行において得られた母数の標本の値を取り、それらを折れ線グラフとしてプロットしたグラフである。定常分布が収束しているかを目視で判断する。たとえば各標本値からヒストグラムを作ることでシミュレーションで得たサンプルの標本分布を近似できる。
次に収束の判断をするための指標として
がある。ここでは連鎖の数で、
は系列間分散*1、
は系列間分散*2を表す。もし標本が適切な事後分布から生成され、かつ標本サイズが充分に大きければ、
は
に収束する。この指標は標本列の収束性および標本が初期値の依存を脱却したか否かを見ることもできる。すなわち標本が局所最適に陥っていないかを確認できる。
は
という判断ルールを提案している*3。
最後に、分散の観点から標本の収束を確認すべく実効サンプルサイズ(
)を与える。これは標本間に相関が無いと想定した場合の標本サイズを表している。
ある母数の推定量
を得たとき、それの相関を持つ系列の平均
の分散
に対して
が成り立つ。ここでは連鎖の数、
は繰り返し回数で、
は
のラグ
の自己相関(系列相関)を表す。もし各
連鎖の繰り返しが独立であるならば、
は単純に
に一致し、標本サイズは
に一致する。相関の存在する中では、実効標本サイズは
で定義される。ただし自己相関は未知であるから、自己相関をその推定値に置き換えた
を実際には用いる。が
になるべく近いことが望ましいが、
は
*4を満たすまではシミュレーションをすべきだというルールを提案している。
上の例では、トレースプロットを見る限り、目立った異常は生じていない。またはすべて
とほぼ収束していると言えそうである。さらに
は
*5に概ね近い値になっているため、これも満たしたと言い切ることにする。