以下の書籍

を中心に時系列解析を勉強していきます。
前回
15. 一般状態空間モデルの一括解法
15.4 推定精度向上のためのテクニック
は繰り返し数を無限にした際に理想的な性能を達成することができる。これに対して現実の実装では繰り返し数は有限であるから、その理想的な性能よりも劣化する。そのためより少ない繰り返し数で性能を維持すべく、アルゴリズムから実装に及ぶまで様々な改善手法が提案されている。
15.4.1 線形・ 型状態空間モデルが部分的に当てはまる場合
型状態空間モデルが部分的に当てはまる場合
一部の一般状態空間モデルでは、部分的に線形・型状態空間モデルが部分的に当てはまることがある。この場合、カルマンフィルタを解法の部品として用いる方法がある。
このような方法が活用できるのは、一般状態空間モデルにおける状態が線形型状態空間モデルに従う部分とそれ以外に分離できる場合である。たとえば母数が未知の線形
型状態空間モデルにおいて、母数を確率変数と捉え、状態と母数の同時事後分布
を推定する場合である。母数が既知であったり、母数が道でも状態とは別に予め最尤推定などで求めた値を用いたりすれば、線形
型状態空間モデルだったところが、状態と母数を併せて推定すべく一般状態空間モデルとしたのだった。そのため母数が分かれば線形
型状態空間モデルに帰着し得る。
そのための方法の1つが、確率変数として考えている母数だけをで推定し、その推定結果を
で利用するものである。この場合、
がの推定対象である。このとき
の定理から
が成り立つ。は線形
型状態空間モデルの尤度であるから、
とすればよい(および
は一期先予測尤度の平均および分散である。)。
には無情報事前分布を設定することが多い。こうして得た
の推定結果の代表値を点推定値として
に用いる。
2つ目の方法は、同時事後分布からの標本を得る方法で、前向きフィルタ後ろ向きサンプリング(
)が利用できる。1項目の
は
が既知という条件となっており、線形
型状態空間モデルに従う。ここからのサンプリングには
を用いる。2項目の
のサンプリングには1つ目の方法を適用する。まずは2項目からのサンプリングを行ない、その後
を用いて1項目のからサンプリングを行ない、状態の標本を生成する。
いずれの方法でも、による推定対象は母数に限定される。
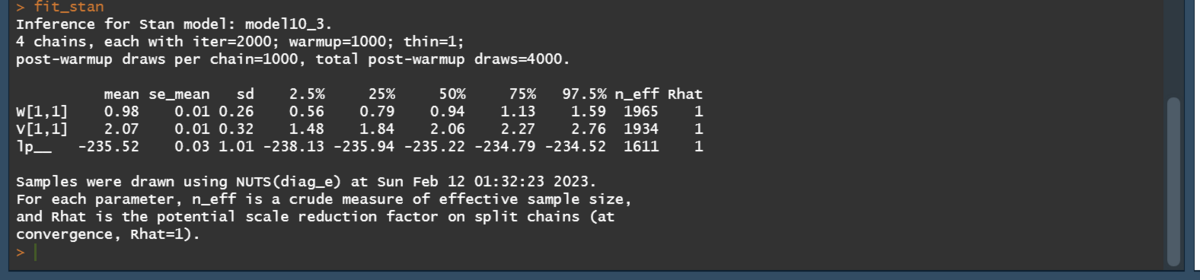
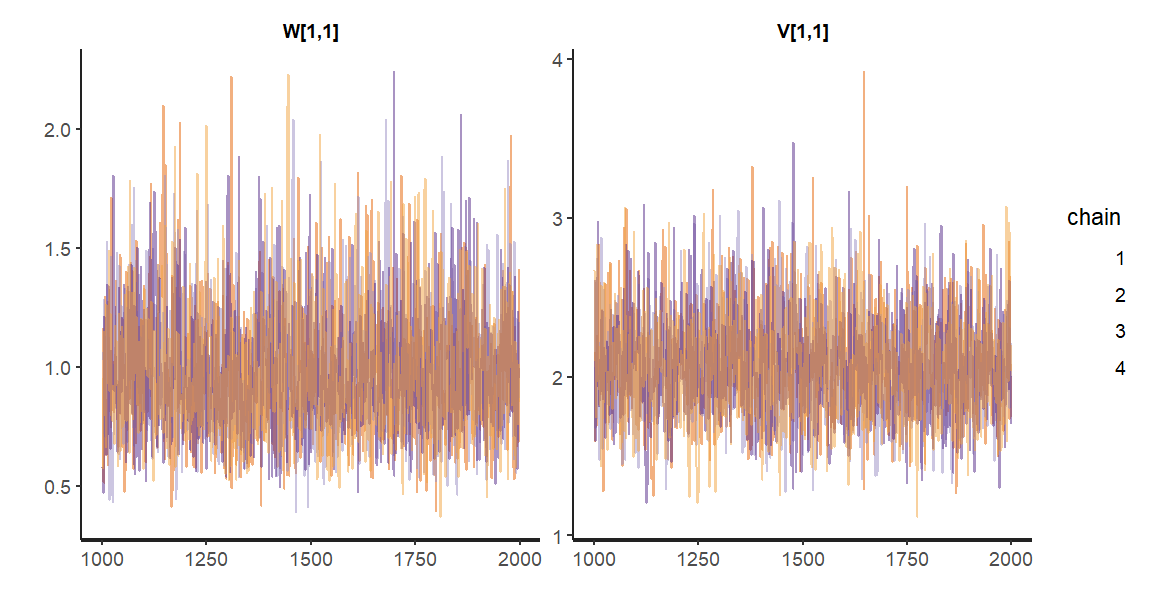
set.seed(123) library("rstan") library("dlm") # stanの事前設定 rstan_options(auto_write = T) options(mc.cores = parallel::detectCores()) theme_set(theme_get() + theme(aspect.ratio = 3/4)) # load(file = "C:/Users/Julie/Desktop/ArtifitialLocalLevelModel.RData") # モデル:生成・コンパイル stan_mod_out <- stan_model(file = "C:/Users/Julie/Desktop/model10_3.stan") # 平滑化:実行(サンプリング) dim(mod$m0) <- 1 fit_stan <- sampling(object = stan_mod_out, data = list(t_max = t_max, y = matrix(y, nrow = 1), G = mod$G, F = t(mod$F), m0 = mod$m0, C0 = mod$C0), pars = c("W","V"), seed = 123 ) # 結果 fit_stan traceplot(fit_stan, pars = c("W", "V"), alpha = 0.5) # 必要なサンプリング結果を取り出す stan_mcmc_out <- rstan::extract(fit_stan, pars = c("W", "V")) # FFBSの前処理 it_seq <- seq_along(stan_mcmc_out$V[,1,1]) progress_bar <- txtProgressBar(min = 1, max = max(it_seq), style = 3) # FFBSの本処理 x_FFBS <- sapply(it_seq, function(it){ # 進捗バー setTxtProgressBar(pb = progress_bar, value = it) mod$W[1,1] <- stan_mcmc_out$W[it,1,1] mod$V[1,1] <- stan_mcmc_out$V[it,1,1] return(dlmBSample(dlmFilter(y = y, mod = mod))) }) # FFBSの後処理 x_FFBS <- t(x_FFBS[-1,]) # 周辺化 s_FFBS <- colMeans(x_FFBS) s_FFBS_quant <- apply(x_FFBS, 2, FUN = quantile, probs = c(0.25, 0.5, 0.75)) s_FFBS_quant