今回やりたいこと
確率試行のシミュレーションをJuliaで扱ってみる。
")
を参照する。
1. 統計モデリングと推論
1.1 数値積分による推論計算
数値積分を使って母数の事後分布を計算することもできる。
まず今回生成してきた過程は、
で与えることができる。このとき同時分布として書くと、
である。ここで
である。
条件付き分布の定義から
が得られる。
分子においておよび
を計算する必要がある。しかし
は
分布の積で
は一様分布として与えられる。一方で
で計算する。しかしこの右辺の計算はよほどシンプルなモデルを選ばない限り積分計算は困難である。
新しいデータに対する予測分布は
として計算すればよい。
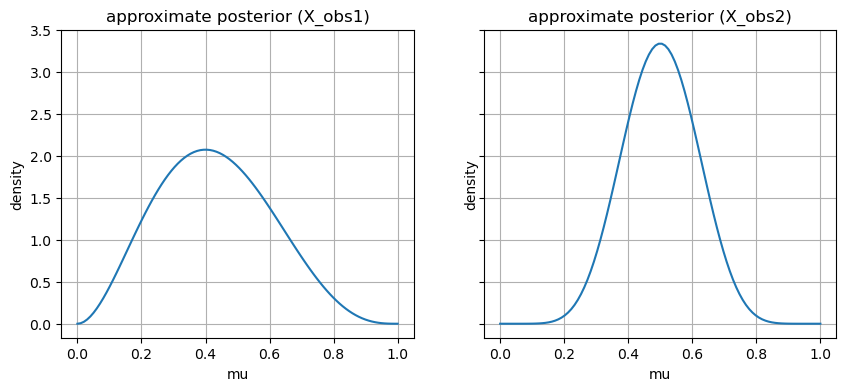
########################## ### 事後分布を計算する ### ########################## using Distributions, PyPlot, LinearAlgebra # グラフの軸やタイトルを設定する関数 function set_options(ax, xlabel, ylabel, title; grid = true, gridy = false, legend = false) ax.set_xlabel(xlabel) ax.set_ylabel(ylabel) ax.set_title(title) if grid if gridy ax.grid(axis = "y") else ax.grid() end end legend && ax.legend() end p_joint(X,mu) = prod(pdf.(Bernoulli(mu),X)) * pdf(Uniform(0,1), mu) # 数値積分 function approx_integration(mu_range, p) Delta = mu_range[2]-mu_range[1] X -> sum([p(X,mu) * Delta for mu in mu_range]), Delta end mu_range = range(0, 1, length =100) # 数値積分の実行 p_marginal, Delta = approx_integration(mu_range, p_joint) X_obs1 = [0,0,0,1,1] X_obs2 = [0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1] # それぞれの周辺尤度の近似計算 println("$(p_marginal(X_obs1)), $(p_marginal(X_obs2))") mus =range(0,1, length = 100) fig, axes = subplots(1, 2, sharey = true, figsize = (10,4)) for (i, X_obs) in enumerate([X_obs1, X_obs2]) posterior(mu) = p_joint(X_obs, mu) / p_marginal(X_obs) axes[i].plot(mus, posterior.(mus)) set_options(axes[i], "mu", "density", "approximate posterior (X_obs$(i))") end ### 予測分布を計算 # 積分の中身の式 posterior1(mu) = p_joint(X_obs1, mu) / p_marginal(X_obs1) posterior2(mu) = p_joint(X_obs2, mu) / p_marginal(X_obs2) p_inner1(x, mu) = pdf.(Bernoulli(mu), x) * posterior1(mu) p_inner2(x, mu) = pdf.(Bernoulli(mu), x) * posterior2(mu) # 母数muに対する積分 mu_range = range(0, 1, length = 100) pred1, Delta1 = approx_integration(mu_range, p_inner1) pred2, Delta2 = approx_integration(mu_range, p_inner2) println("$(pred1(1)), $(pred2(1))")
 |