Rについて
:データ解析の基礎から最新手法まで")
をベースに学んでいく。
今回は対応分析(PP.85-96)を扱う。
7. 対応分析
対応分析(コレスポンデンス分析)は1970年代から普及し始めた質的データの解析方法である。類似概念としては数量化Ⅲ類などがある。
大きな表におけるカテゴリカル変数の関係を要約的に記述することができる。また次元を縮約し少ない次元で度数表における行と列の関係をグラフィカルに表示できる。この手法の利点を引き出すには以下の3つの基準が満たされる必要がある*1:
| (1) | 単純な統計解析で構造を発見するのが困難なほどデータ行列が巨大であるか。 | |
| (2) | カテゴリー間の距離計算が意味をもつように変数は同質であるか。 | |
| (3) | 構造が未知のデータであるか。 |
他方で、
| (1) | 異なるデータセットに含まれる点の距離は定義できない。 | |
| (2) | 効果、もしくは交互作用に対する優位性検定は含まれない。 |
という欠点がある。
7.1 対応分析の基本的な考え方
対応分析の基本的な考え方は「分割表において行の項目と劣の項目の相関が最大になるように行・列の双方を並び替え、関連性が強いもの同士が近似になるような値を取るように処理を行う」というものである。
まず簡単な度数に関する分割表を考える。行列
で表されるデータ行列について、その各要素を総度数
で割ったデータを
とおく。
データ行列
合計 |
||||||||
個体 |
||||||||
個体 |
||||||||
個体 |
||||||||
個体 |
||||||||
合計 |
分割表の問題では、通常カイ二乗統計量を用いる。カイ二乗統計量の各セルの値は
で与えられる。対応分析はデータ行列または
を次の式で変換したデータの固有値問題に帰着する。
行列を考えたときに分割表の列の効果は
、行の効果は
の固有ベクトル
をそれぞれ
で規格化した
を用いる。の固有値が
である場合、
が成り立つ。
対応分析は分散をカイ二乗統計量=距離で計算することでその独自の特徴が現われる。
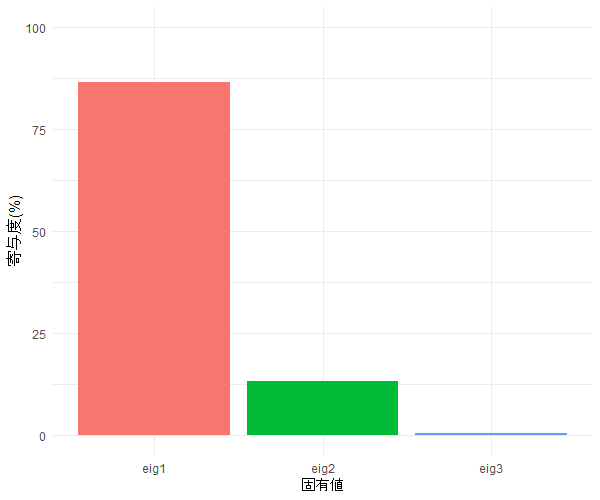
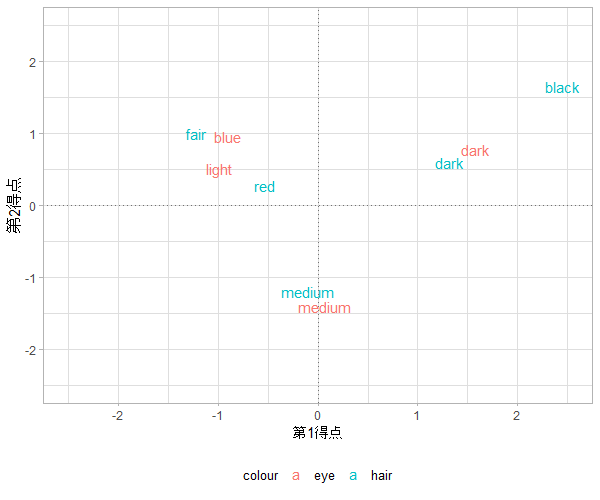
7.2 Rのスクリプトと実行結果
library(MASS) library(ggplot2) # データ data(caith) # 英国居住者の目の色と髪の色に関する集計結果 # データを見てみる caith # 対応分析を実施 corres_anl <- corresp(x = caith,nf = min(nrow(caith),ncol(caith)) - 1) summary(corres_anl) # 正準相関 caith_eig <- corres_anl$cor^2 # 固有値 round(x = caith_eig,digits = 3) df_contributions <- data.frame(vars = c("eig1","eig2","eig3"),cnt = round(100 * caith_eig / sum(caith_eig),2)) g <- ggplot(df_contributions,aes(x = vars, y = cnt, fill = vars)) + geom_bar(stat = "identity") g <- g + theme_minimal() + theme(plot.title = element_text(hjust = 0.5),legend.position = "none", legend.title=element_text(size = 7), legend.text=element_text(size = 7)) g <- g + xlab("固有値") + ylab("寄与度(%)") g <- g + ylim(c(0,100)) plot(g) # 得点のバイプロット:第1得点、第2得点で殆どを説明できるので、2次元 df_rscore <- corres_anl$rscore df_cscore <- corres_anl$cscore df_rscore <- data.frame(names = row.names(df_rscore), colour = rep("eye",nrow(df_rscore)), x = df_rscore[,1], y = df_rscore[,2]) df_cscore <- data.frame(names = row.names(df_cscore), colour = rep("hair",nrow(df_cscore)), x = df_cscore[,1], y = df_cscore[,2]) df_data <- rbind(df_rscore,df_cscore) # 見やすいように軸 num_max <- max(abs(df_data[,"x"]),abs(df_data[,"y"])) vc_lim <- c(-round(num_max,1),round(num_max,1)) # 得点のプロット g2 <- ggplot(df_data,aes(x = x, y = y,label = names, color = colour)) + geom_text() g2 <- g2 + theme_light() + theme(plot.title = element_text(hjust = 0.5),legend.position = "bottom", legend.title=element_text(size = 10), legend.text=element_text(size = 10)) g2 <- g2 + xlab("第1得点") + ylab("第2得点") g2 <- g2 + xlim(vc_lim) + ylim(vc_lim) g2 <- g2 + geom_vline(xintercept = 0,linetype = 3,size = 0.5, alpha = 0.7) g2 <- g2 + geom_hline(yintercept = 0,linetype = 3,size = 0.5, alpha = 0.7) plot(g2)
caithに適用した結果(左:寄与度、右:第1得点・第2得点のプロット)
 |
 |