いい加減時代の潮流に乗ろうということで機械学習を学びたいと思う。またRはともかくとしてPythonは未経験であるため、丁度良い書籍として
 (機械学習の数理100問シリーズ)")
")
を用いることにする。
5. 正則化
以下、線形回帰を考えるが、一般性を失うことなく切片項とし、標本数を
、変数の数を
として
とする。
5.1 Ridge
行列が特異ではないとも、その行列式が小さい場合、信頼区間が大きくなるなど推定値の信頼性が下がる。そこで定数
を用いて
を最小化することで母数(ベクトル)を推定する*1。これを
という。
目的関数を
で微分すると
を得るから、が正則ならば、
が得られる。
もしならば
が非負定値であることからその固有値
はすべて非負である。したがって
に対して
と、すべての固有値は正である。このためは正則であることが保証される。これは
の大小に依存しない。もし
ならば
は階数が
未満で特異である。したがって
である。
5.2 劣微分
のように絶対値が入ることで微分可能でない点をもつ関数にも微分をできるように概念を拡張できれば、最適化をより柔軟に適用し得る。そこで微分の概念を拡張する。
前提としてが凸関数であることを仮定する。
5.3 Lasso
定数を用いて
を最小化することで母数(ベクトル)を推定する方法を
という。
の解析には劣微分を用いる。簡単のため、
を仮定し、
とおく。
このときの
に関する劣微分*2を求めれば、
の
での劣微分が
であるから、
である。したがって
が得られる。
もし規格化の仮定が満たされない場合は、
において、を固定して
を更新する。これを
まで何度も繰り返して収束させる。そして各段階で
を更新する際に
をその残差
で置き換える。また
においてとして、
を更新する。
5.4 RidgeとLassoの比較
および
はいずれも
が大きくなるにつれて係数の絶対値は減少し
に近づいていく。
は
が一定値以上になると係数値が
となり、そのタイミングが変数ごとに相違するために変数選択に用いることができる。このように
は変数選択に用いることができる。
簡単のためとすれば、この最適化問題は、中心が
であるような
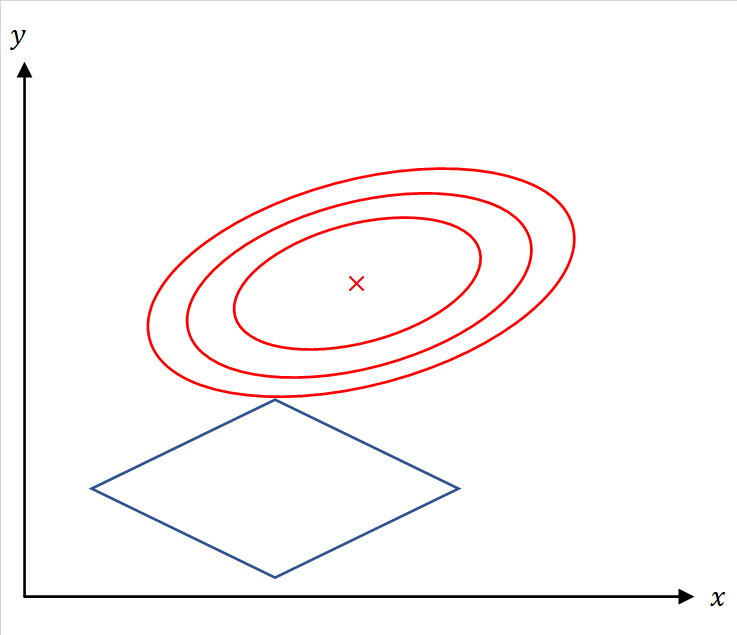
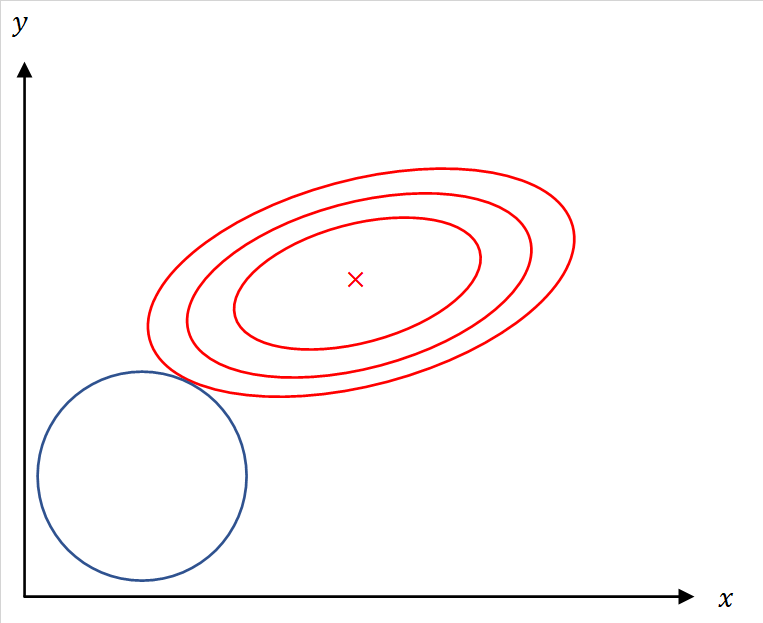
5.5 λの設定方法
はクロスバリデーションを適用して決定するのが多い。
の場合、
パッケージを用いると便利である。
############### ### λの設定 ### ############### library("glmnet") df <- read.table(file = "C:/Users/Julie/Downloads/crime.txt",header = F,sep = ",") X <- as.matrix(df[,3:ncol(df)]) y <- df[,1] cv_fit <- cv.glmnet(X,y) # クロスバリデーションによるλ設定 plot(cv_fit) lambda_min <- cv_fit$lambda.min fit <- glmnet(X, y, lambda = lambda_min) fit$beta
5.6 Rでのシミュレーション
5.6.1 Ridge
################# ### Ridge回帰 ### ################# library("ggplot2") # Ridge ridge <- function(X, y, lambda = 0){ X <- as.matrix(X) X <- scale(X) # 規格化 p <- ncol(X) # 変数の数 n <- length(y) # 標本数 X_bar <- array(dim = p) for(i in 1:p){ X_bar[i] <- mean(X[,i]) X[,i] <- X[,i] - X_bar[i] } y_bar <- mean(y) y <- y - y_bar beta <- drop(solve(t(X) %*% X + n* lambda * diag(p)) %*% t(X) %*% y) beta_0 <- y_bar - sum(X_bar * beta) return(list(beta = beta, beta_0 = beta_0)) } # シミュレーション vc_names <- c("警察への年間資金","25歳以上で高卒人数の割合","16-19歳で高校に通っていない人の割合", "18-24歳で大学生の割合","25歳以上で4年制大卒の割合") df <- read.table(file = "(ファイルパス)",header = F,sep = ",") X <- df[,3:ncol(df)] y <- df[,1] p <- ncol(X) lambda_seq <- seq(0, 100, 0.1) coef_seq <- lambda_seq df_betas <- data.frame(matrix(NA,nrow = p, ncol = length(lambda_seq))) colnames(df_betas) <- 1:ncol(df_betas) # Ridge推定 for(lambda in lambda_seq){ df_betas[,which(lambda_seq==lambda)] <- ridge(X,y,lambda)$beta } df_betas_graph <- NULL for(i in 1:nrow(df_betas)){ df_betas_graph <- rbind(df_betas_graph, data.frame(lambda = lambda_seq, var = vc_names[i], estimate = unlist(df_betas[i,])) ) } # 図示 g <- ggplot(df_betas_graph,aes(x = lambda,y = estimate, group = var, color = var)) + geom_line() g <- g + xlab("λ") + ylab("推定値")+ labs(title = "Ridge回帰による各母数の推定値",color = "") g <- g + theme_classic() + theme(plot.title = element_text(hjust = 0.5), legend.position = c(1, 1), legend.justification = c(1, 1), legend.title=element_text(size = 12), legend.text=element_text(size = 12)) g <- g + geom_hline(yintercept = 0, linetype = 1) plot(g)
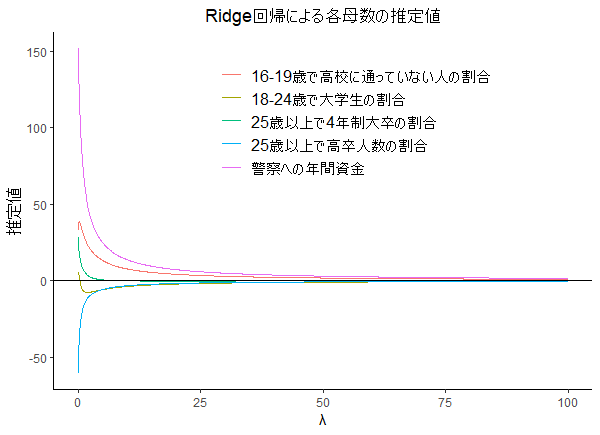 |
5.6.2 Lasso
################# ### Lasso回帰 ### ################# soft_th <- function(lambda,x){ return(sign(x) * pmax(abs(x) - lambda,0)) } lasso <- function(X, y, lambda = 0){ X <- as.matrix(X) X <- scale(X) p <- ncol(X) n <- length(y) X_bar <- array(dim = p) for(j in 1:p){ X_bar[j] <- mean(X[,j]) X[,j] <- X[,j] - X_bar[j] } y_bar <- mean(y) y <- y - y_bar eps <- 1 beta <- array(0, dim = p) beta_old <- array(0, dim = p) while(eps > 0.0001){ for(j in 1:p){ r <- y - X[,-j]%*%beta[-j] beta[j] <- soft_th(lambda, sum(r * X[,j])/n) } eps <- max(abs(beta - beta_old)) beta_old <- beta } beta_0 <- y_bar - sum(X_bar * beta) return(list(beta = beta, beta_0 = beta_0)) } ### vc_names <- c("警察への年間資金","25歳以上で高卒人数の割合","16-19歳で高校に通っていない人の割合", "18-24歳で大学生の割合","25歳以上で4年制大卒の割合") df <- read.table(file = "(ファイルパス)",header = F,sep = ",") X <- df[,3:ncol(df)] y <- df[,1] p <- ncol(X) lambda_seq <- seq(0, 100, 0.1) coef_seq <- lambda_seq df_betas <- data.frame(matrix(NA,nrow = p, ncol = length(lambda_seq))) colnames(df_betas) <- 1:ncol(df_betas) # Lasso推定 for(lambda in lambda_seq){ df_betas[,which(lambda_seq==lambda)] <- lasso(X,y,lambda)$beta } df_betas_graph <- NULL for(i in 1:nrow(df_betas)){ df_betas_graph <- rbind(df_betas_graph, data.frame(lambda = lambda_seq, var = vc_names[i], estimate = unlist(df_betas[i,])) ) } # 図示 g <- ggplot(df_betas_graph,aes(x = lambda,y = estimate, group = var, color = var)) + geom_line() g <- g + xlab("λ") + ylab("推定値")+ labs(title = "Lasso回帰による各母数の推定値",color = "") g <- g + theme_classic() + theme(plot.title = element_text(hjust = 0.5), legend.position = c(1, 1), legend.justification = c(1, 1), legend.title=element_text(size = 12), legend.text=element_text(size = 12)) g <- g + geom_hline(yintercept = 0, linetype = 1) plot(g)
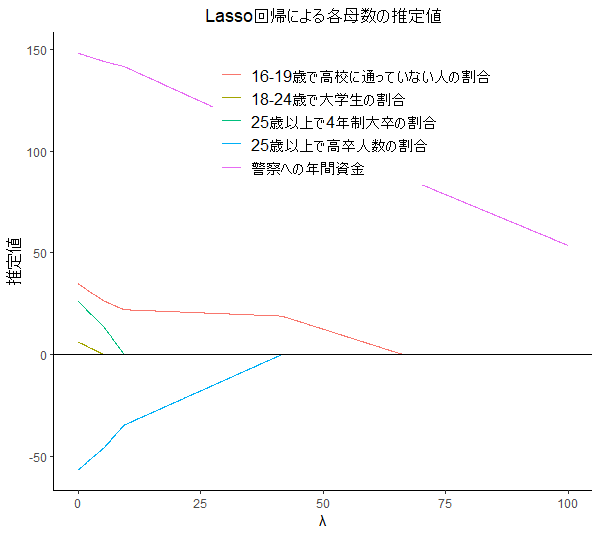 |
5.7 Pythonによるシミュレーション
5.7.1 Ridge
import numpy as np import copy import matplotlib.pyplot as plt %matplotlib inline import japanize_matplotlib def ridge(x,y, lam = 0): X = copy.copy(x) n, p = X.shape X_bar = np.zeros(p) s = np.zeros(p) for j in range(p): X_bar[j] = np.mean(X[:,j]) for j in range(p): s[j] = np.std(X[:,j]) X[:,j] = (X[:, j] - X_bar[j])/s[j] y_bar = np.mean(y) y = y - y_bar beta = np.linalg.inv(X.T@X + n * lam * np.eye(p))@X.T@y for j in range(p): beta[j] = beta[j] / s[j] beta_0 = y_bar - X_bar.T@beta return {'beta': beta, 'beta_0': beta_0} # テストデータ df = np.loadtxt("C:/Users/Julie/Downloads/crime.txt", delimiter = ",") X = df[:,[i for i in range(2,7)]] p = X.shape[1] y = df[:,0] lambda_seq = np.arange(0,50,0.5) plt.xlim(0,50) plt.ylim(-7.5,15) plt.xlabel("lambda") plt.ylabel("beta") labels = ["警察への年間資金","25歳以上で高卒人数の割合","16-19歳で高校に通っていない人の割合", "18-24歳で大学生の割合","25歳以上で4年制大卒の割合"] for j in range(p): coef_seq = [] for l in lambda_seq: coef_seq.append(ridge(X,y,l)['beta'][j]) plt.plot(lambda_seq, coef_seq, label = "{}".format(labels[j])) plt.legend(loc = "upper right")
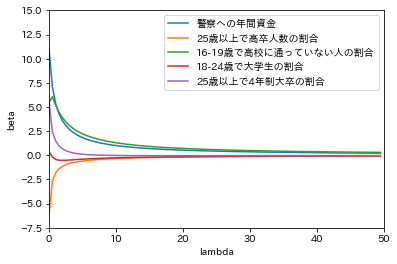 |
5.7.2 Lasso
############# ### Lasso ### ############# import numpy as np import copy def soft_th(lam, x): return np.sign(x) * np.maximum(np.abs(x) - lam, 0) def lasso(x,y,lam = 0): X = copy.copy(x) n, p = X.shape X_bar = np.zeros(p) s = np.zeros(p) for j in range(p): X_bar[j] = np.mean(X[:,j]) for j in range(p): s[j] = np.std(X[:,j]) X[:,j] = (X[:,j]-X_bar[j])/s[j] y_bar = np.mean(y) y = y - y_bar eps = 1 beta = np.zeros(p) beta_old = np.zeros(p) while eps > 0.0001: for j in range(p): idx = list(set(range(p)) - {j}) r = y - X[:,idx]@beta[idx] beta[j] = soft_th(lam,r.T@X[:,j]/n) eps = np.max(np.abs(beta - beta_old)) beta_old = beta for j in range(p): beta[j] = beta[j]/s[j] beta_0 = y_bar - X_bar.T@beta return {'beta':beta, 'beta_0':beta_0} # テストデータ df = np.loadtxt("C:/Users/Julie/Downloads/crime.txt", delimiter = ",") X = df[:,[i for i in range(2,7,1)]] p = X.shape[1] y = df[:,0] lasso(X,y,20) lambda_seq = np.arange(0,200,0.5) plt.xlim(0,200) plt.ylim(-10,20) plt.xlabel("lambda") plt.ylabel("beta") labels = ["警察への年間資金","25歳以上で高卒人数の割合","16-19歳で高校に通っていない人の割合", "18-24歳で大学生の割合","25歳以上で4年制大卒の割合"] for j in range(p): coef_seq = [] for l in lambda_seq: coef_seq.append(lasso(X,y,l)['beta'][j]) plt.plot(lambda_seq, coef_seq, label = "{}".format(labels[j])) plt.legend(loc = "upper right") plt.title("各λに対する各係数の推定値") ##### from sklearn.linear_model import Lasso from sklearn.linear_model import LassoCV Las = Lasso(alpha = 20) Las.fit(X,y) Las.coef_ # alphasに指定した値をグリッドサーチする Lcv = LassoCV(alphas = np.arange(0.1, 30, 0.1), cv = 10) Lcv.fit(X,y) Lcv.alpha_ Lcv.coef_
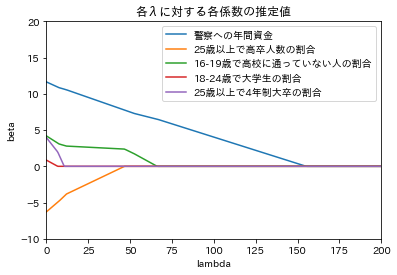 |