仕事上、早々にを使えるようにしないといけないため、

を基に学んでいく。
3. NumPyの基礎:配列とベクトル演算
は"
"の意味で
での数値計算におけるもっとも重要な基本パッケージの1つである。
には以下のような特徴がある:
- 高速な行列計算と柔軟なブロードキャストを提供する効率的な多次元配列である
- 高速に動作し、呼出しにループ記法を必要としない標準的な数学関数
- ディスクへの配列の読み書きに加え、メモリマップファイル機能を提供する入出力機能
- 行列計算、乱数生成、
変換といった機能
、
、
へのインターフェース
は
言語呼び出しの
があり、相互間へデータを渡すことができる。そのため
、
、
で書かれた既存のコード資産のラッパーとしての位置づけを獲得してきた。
はそれ自身が数理モデリングやデータ分析手法を提供する訳ではないものの、
の配列や配列思考の計算手法を知っておくと、
のような配列志向のツールを用いるのに便利である。
- ベクトル化記法による高速な計算。データの変更、整頓、取り出しやフィルタリング、変換といったあらゆるデータ操作。
- 一般的な配列操作。ソートや重複除外操作、集合演算。
- 効率的な記述統計学的データ操作。それに必要なデータの結合・要約。
- 種類の異なるデータセットに対する統合や結合などのデータ整理や関係データ処理。
- 配列内での条件記述。ループを記述することなく配列内で直接
-
-
相当の制御を記述する。
- グループ単位でのデータ操作。
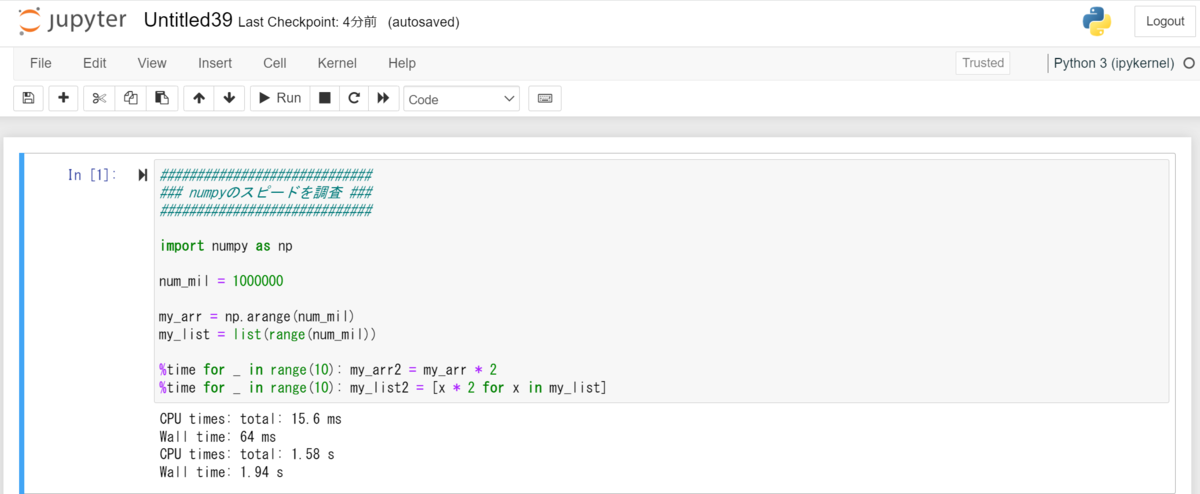
############################# ### numpyのスピードを調査 ### ############################# import numpy as np num_mil = 1000000 my_arr = np.arange(num_mil) my_list = list(range(num_mil)) %time for _ in range(10): my_arr2 = my_arr * 2 %time for _ in range(10): my_list2 = [x * 2 for x in my_list]
3.1 NumPy ndarray:多次元配列オブジェクト
に対する算術操作は、その配列要素全てに作用する。
import numpy as np data = np.random.randn(2, 3) # ndarrayに対する算術演算はすべての要素に適用される print(data) print(data*10) print(data+data) print(data.shape) data.dtype
3.1.1 ndarrayの生成
##################### ### ndarrayの生成 ### ##################### data1 = [6,7.6,8,0,1] arr1 = np.array(data1) print(arr1) data2 = [[1,2,3,4],[5,6,7,8]] arr2 = np.array(data2) print(arr2) # ListのListで定義されるNumPy配列は2次元配列である print(arr2.ndim) print(arr2.shape) print(arr1.dtype) print(arr2.dtype) # np.zeros(10) np.ones(10)
| 関数 | 説明 |
|---|---|
| 入力にリスト、タプル、 |
|