Rについて
:データ解析の基礎から最新手法まで")
をベースに学んでいく。
今回は生存分析(PP.296-311)を扱う。
22. 生存分析
生存分析は事象が起きるまでの時間とその事象との間の関係に焦点を当てる手法である。応用先には倒産、機械の故障、疾患や死亡の分析があり、これらを総称して広義の死亡と見なすことにする。
生存時間に関する試験・観測では、治療の中止や転院などにより、データが脱落する場合がある。また研究の終了時点では死亡に関するデータが入手できないことが起こり得る。このようなことを打ち切りが生じたという。
生存時間を確率変数として、以下のように確率密度関数
を定義する:
である。ここでは生存確率である。累積確率分布関数を
で表すと
となり、イベントが時点まで生起していない確率である生存関数
は
で表される。イベントがある時点までに生起していないという条件の下で、その直後の瞬間にイベントが生起する(瞬間死亡率を表す)ハザード関数
は
となる。生存関数とハザード関数
および累積ハザード関数
との関係は
で表すことができる。
生存分析は生存時間に影響を与える時間以外の共変量がパラメータとしてモデルに導入されているか否か、生存時間の分布形に特定の確率分布を仮定するか否かによって
| ノンパラメトリックモデル | 共変数を導入しない、分布を仮定しない。 | |
|---|---|---|
| セミパラメトリックモデル | 共変数を導入する、分布を仮定しない。 | |
| パラメトリックモデル | 共変数を導入する、分布を仮定する。 |
と分類できる。
22.1 ノンパラメトリックモデル
ノンパラメトリックな生存時間推定には
- 経験分布による推定法
- ハザード関数による推定法
の2つがある。
22.1.1 経験分布による推定
打ち切りの無い完全データであれば、経験分布を用いて
で推定できる。
22.1.2 ハザード関数による推定
-
推定量
を用いて(は時点
における死亡数、
は時点
の直前までイベントが生じる可能性のある観察対象者の数である。)、累積ハザード関数およびその推定量はそれぞれ
を-
推定量と呼ぶ。
library("MASS") library("survival") library("survminer") ### 生存時間データオブジェクトを生成 Surv(gehan$time,gehan$cens) ### survfitを適用 ge_sf <- survfit(formula = formula(Surv(time, cens)~treat), data = gehan) ggsurvplot(ge_sf,conf.int=T, conf.int.style = "ribbon", conf.int.alpha = 0.5, xlab = "生存時間", ylab = "生存確率", legend = "top", legend.title = "凡例", legend.labs=c("6-MP投与群","対照群"))
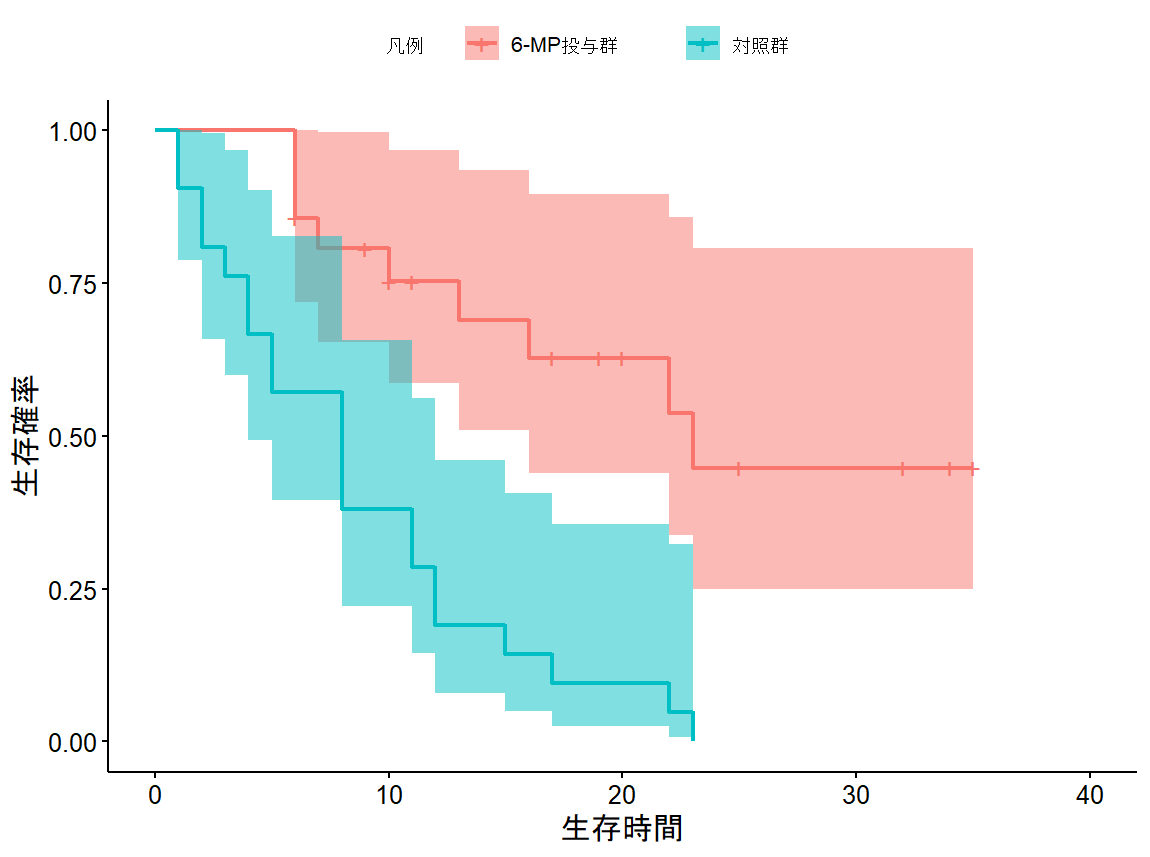
22.1.1 生存関数の検定
2群以上の観測値が得られたときに、群ごとの生存曲線間の差の有意性を検定する場合がある。頻用されるのは-
検定法で、群ごとにイベントありと無しとを集計したクロス表のカイ二乗値の推定値を検定統計量とするものである。
survdiff(Surv(time)~treat,data=gehan, rho = 0) # p =0.003なので帰無仮説を棄却
22.2 セミパラメトリックモデル
生存解析に用いるセミパラメトリックモデルとして比例ハザードモデルがある。ハザード関数
に対して、すべて可能な
に対し
が成り立つとき、
と
は比例するという。共変量
を持つハザード関数
とし、
を変数とする関数
とあるハザード関数
を用いて、すべての
と
について
とするモデルを比例ハザードモデルという。
は条件付き確率の部分尤度
を最大化することで推定できる。ここではイベント数、
はイベント時点、
各時点におけるリスクの集合である。
22.2.1 Cox比例ハザードモデルの推定
パッケージには
比例ハザードモデルの推定を行なう
()関数がある。
############################# ### Cox比例ハザードモデル ### ############################# library("survival") cox_kidney <- coxph(formula = formula(Surv(time,status)~sex+disease),data = kidney) summary(cox_kidney) kidney_fit <- survfit(cox_kidney) summary(kidney_fit) plot(kidney_fit)
22.2.2 残差分析
比例ハザードモデルでは、打切りデータが存在することもあり、一般線形回帰モデルの残差分析ほど単純ではない。そのためマルチンゲール残差など様々な残差が提案されている。
残差はで呼び出すことができる。
scatter.smooth(residuals(cox_kidney))
22.2.3 ハザードの比例性分析
()関数を用いることで、シェーンフィールド残差を用いて、
における仮説
の検定に必要な関数を返す。
zph_kidney <- cox.zph(cox_kidney) zph_kidney plot(zph_kidney)
スプライン平滑化曲線の傾向に、時間に伴う明らかな変化パターンが見られなければ、比例ハザードの仮定に問題が無いと言われる。
個別の変数に比例ハザードの仮定が満たされていない場合には、変数の交互作用をモデルに導入するような試みが必要になる。