統計学を真剣に学ぶ人のために、個人的にまとめているノートを公開する。
底本として

を用いる。
8. 統計的仮説検定
8.3 良い検定手法の定義:一様最強力検定・不偏検定・尤度比検定
「“良い”検定」とは何か。伝統的な検定手法に立脚すれば、前述のとおり第1種の過誤を犯す確率を有意水準に抑えたうえで対立仮説のもとでの検出力を最大にする(第2種の過誤を犯す確率を最小化する)ものである。こうしたものを与える条件を具体的に考えるために有用な概念が「(一様)最強力検定」「不偏検定」「尤度比検定」である。
「(一様)最強力検定」とは検出力の高い検定の方が“良い”検定であるという、言ってみれば当たり前の条件を明言化するための考えである。しかしそれはすべての検定において常に存在するというわけではない。そこでもし(一様)最強力検定が存在しないのであれば、(一様)最強力検定が存在するように検定族を制約する「条件」を加えることを考えればよく、そのための条件が検定における「不偏性」である。
8.3.4 尤度比検定
ここまでは-
の補題という前提で尤度比を導入したが、これはその前提が無くとも考えることができる。
確率変数*1に対して
を同時密度関数とするとき、一般的な仮説検定問題
を考える。このとき
を尤度比(統計量)という。さらにこの対数を取ったを対数尤度比という。帰無仮説および対立仮説の双方が単純仮説の場合、尤度比検定統計量は
-
の補題に現れた尤度比に一致する。
帰無仮説のもとでの最尤推定量および対立仮説のもとでの最尤推定量
としたときに棄却域を
としたものを尤度比検定と呼ぶ。
尤度比検定は複合仮説検定問題を単純仮説問題
に置き換えて-
の補題を適用した形式の検定方式である。そこから推察できるように、尤度比検定は、
| (1) | 尤度比検定 |
|
| (2) |
といった性質を持つ“良い”検定であると言える。
ただし具体的な問題において棄却限界を正確に求めるのが困難な場合が多い。それでも、標本サイズ
が十分に大きければ、その値がカイ二乗分布に近似的に従うことが知られており、そこから近似値を求めることは可能である。
すなわち、仮説検定
において有意水準の尤度比検定を考えると、自由度
のカイ二乗分布の上側
%点を
とすれば、
を棄却域とすることで、漸近的に有意水準を得ることができる。このように、尤度比検定は点推定論における最尤推定のように汎用性に優れる点が利点である。
8.4 仮説検定における精度と標本サイズの関係
検出力関数は当然ながら検定関数
に依存するが、標本サイズである
にも依存する。すなわち、検定関数
の検出力を
とすれば第2種の誤りを犯す確率は
であることに注意すれば、
| (1) | 帰無仮説は限定的である*2から、第1種の誤りを犯す確率(有意水準) |
|
| (2) | 対立仮説は様々な母数などが変化するため、第2種の誤りを犯す確率 |
|
| (3) | 第1種の誤りを犯す確率(有意水準) |
|
| (4) | 第1種の誤りを犯す確率(有意水準) |
|
| (5) | 標本サイズ |
が成り立つ。
であるため、帰無仮説
を可能な限り保障するには検出力を大きくしなければならない。とはいえ標本サイズを無制限に増大させることは困難である。そこで「検定対象となる母数に水準
以上の差(ないし比)がある場合には高い検出力を保障できるようにしたい」のであり、そうした「高い検出力を得るために必要な標本サイズはどの程度なのか」を知るように問題を考えればよい。
例:母平均の両側検定における検出力
正規分布に独立にしたがう確率変数の標本
に対して、有意水準
の仮説検定
を考える。
このとき検定統計量は標準正規分布に従う。したがって
を標準正規分布の片側
%点だとして
である。
次に検出力は、対立仮説
の下で
が成り立つ。
とおけば、検出力
および
に依存して決まることが分かる。
が未知であるから*4、
帰無仮説の下での母平均の正規分布
に従う母集団1と未知母数の正規分布
に従う母集団2に対して、
(1) 一方の母集団の %がもう一方の母集団の
を棄却する。
(2) 一方の母集団の %がもう一方の母集団の
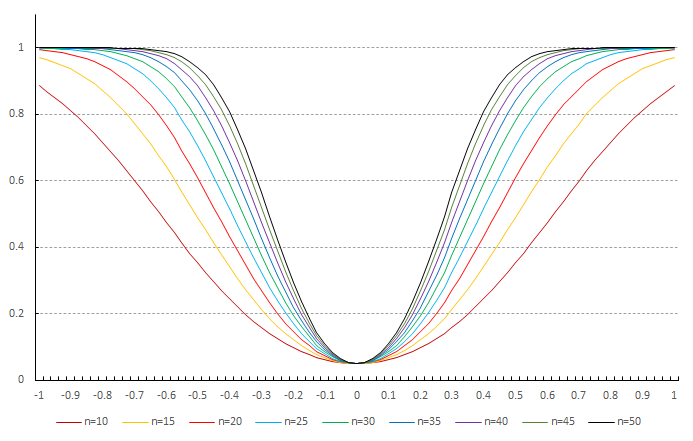
母平均の両側検定における標本サイズ別の検出力曲線
を与えたときに高い検出力
で
が非常に小さい場合を除けば
が成り立つから、
のときに
であればよく、したがって標本サイズ
とすればよい。
参考文献
- Lehmann, E.L., Casella, George(1998), "Theory of Point Estimation, Second Edition", (Springer)
- Lehmann, E.L., Romano, Joseph P.(2005), "Testing Statistical Hypotheses, Third Edition", (Springer)
- Sturges, Herbert A.,(1926), "The Choice of a Class Interval", (Journal of the American Statistical Association, Vol. 21, No. 153 (Mar., 1926)), pp. 65-66
- Wald, A.,(1950), "Statistical Decision Functions", John Wiley and Sons, New York; Chapman and Hall, London
- 上田拓治(2009)「44の例題で学ぶ統計的検定と推定の解き方」(オーム社)
- 大田春外(2000)「はじめよう位相空間」(日本評論社)
- 小西貞則(2010)「多変量解析入門――線形から非線形へ――」(岩波書店)
- 小西貞則,北川源四郎(2004)「シリーズ予測と発見の科学2 情報量基準」(朝倉書店)
- 小西貞則,越智義道,大森裕浩(2008)「シリーズ予測と発見の科学5 計算統計学の方法」(朝倉書店)
- 佐和隆光(1979)「統計ライブラリー 回帰分析」(朝倉書店)
- 清水泰隆(2019)「統計学への確率論,その先へ ―ゼロからの速度論的理解と漸近理論への架け橋」(内田老鶴圃)
- 鈴木 武, 山田 作太郎(1996)「数理統計学 基礎から学ぶデータ解析」(内田老鶴圃)
- 竹内啓・編代表(1989)「統計学辞典」(東洋経済新報社)
- 竹村彰通(1991)「現代数理統計学」(創文社)
- 竹村彰通(2020)「新装改訂版 現代数理統計学」(学術図書出版社)
- 東京大学教養学部統計学教室編(1991)「基礎統計学Ⅰ 基礎統計学」(東京大学出版会)
- 東京大学教養学部統計学教室編(1994)「基礎統計学Ⅱ 人文・社会科学の統計学」(東京大学出版会)
- 東京大学教養学部統計学教室編(1992)「基礎統計学Ⅲ 自然科学の統計学」(東京大学出版会)
- 豊田秀樹(2020)「瀕死の統計学を救え! ―有意性検定から「仮説が正しい確率」へ―」(朝倉書店)
- 永田靖(2003)「サンプルサイズの決め方」(朝倉書店)
- 柳川堯(2018)「P値 その正しい理解と適用」(近代科学社)