いい加減時代の潮流に乗ろうということで機械学習を学びたいと思う。またRはともかくとしてPythonは未経験であるため、丁度良い書籍として
 (機械学習の数理100問シリーズ)")
")
を用いることにする。
6. 非線形回帰
- 説明変数と目的変数の関係が非線形の場合を検討する。
- スプライン回帰を考える。
6.1 多項式回帰
標本を多項式に当てはめることを検討する。最小二乗法と同様に
を最小にするような係数を求めるものとする。
これは通常の重回帰モデルにおいて各説明変数を冪乗に置き換えたものに他ならないから、
とおけば、が正則ならば、
が解となる。ここで
とおいた。
6.2 スプライン回帰
次数が高々次*1であるような
に関する多項式関数
が、ある点
で二次微分までがすべて等しいとき、
が成立する。
これを踏まえて、定義域を複数の期間に分割し各期間に適当な3次関数(曲線)を当てはめる回帰手法をスプライン回帰という。すなわち区間をと分割し、
とおく。
係数はこれまでと同様の手順で推定できる。観測標本
が与えられているとき、
とするとき、平均二乗誤差
が最小になるようなを求めればよい。
の階数が
であれば
は正則であり、
で求まる。
6.3 自然なスプライン関数への回帰
自然なスプライン関数はの
個に分割された区間で2次曲線、両端
で直線に回帰するスプライン関数の変種である。
のにおける2回微分が
であるから、
が成立するから、
を得る。これにより直線部分も一意に求まる。したがって関数は
を指定すれば定まる。
(
はとおけば
と書き換えることができる。
について、
が成り立つから、
が得られる。
他方ででは
について
を得る。したがってに
を代入することで
を得る。
さらにを用いて、
を得る。以上から命題が示された。 )
6.4 シミュレーション
6.4.1 Rによるシミュレーション例
################# ### 多項式回帰### ################# # y=sin(x)+εでテストデータを生成 library("ggplot2") n <- 150 # テストデータの生成 vc_x <- rnorm(n = n,mean = 0,sd = 1) vc_y <- sin(x = vc_x) + rnorm(n = n,mean = 0,sd = 1) # 次数データ vc_p_set <- seq(3,9,2) m <- length(vc_p_set) # 次数を変えながら推定 for(i in 1:m){ p <- vc_p_set[i] mt_x <- rep(1,n) for(j in 1:p){ mt_x <- cbind(mt_x, vc_x^j) } # 母数の推定 beta <- drop(solve(t(mt_x) %*% mt_x) %*% t(mt_x) %*% vc_y) # モデルによる予測値と比較する vc_x2 <- seq(-3,3,0.01) mt_x <- rep(1,length(vc_x2)) for(j in 1:p){ mt_x <- cbind(mt_x, vc_x2^j) } vc_y_pred <- as.vector(beta %*% t(mt_x)) if(i==1){ df_data <- data.frame(matrix(nrow = length(vc_y_pred), ncol = m + 1)) colnames(df_data) <- c("x",paste0(vc_p_set,"次")) df_data[,1] <- vc_x2 df_data[,2] <- vc_y_pred }else{ df_data[,i+1] <- vc_y_pred } } df_data_graph <- data.frame(x = df_data[,1], var = rep(colnames(df_data)[2],nrow(df_data)), y = df_data[,2]) for(i in 3:ncol(df_data)){ df_data_graph <- rbind(df_data_graph,data.frame(x = df_data[,1], var = rep(colnames(df_data)[i],nrow(df_data)), y = df_data[,i])) } df_data_org <- data.frame(x = vc_x, y = vc_y) vc_x_lim <- c(min(vc_x)-0.05,max(vc_x)+0.05) vc_x_lim <- round(vc_x_lim,digits = 1) vc_y_lim <- c(min(c(df_data_org[,"y"],df_data_graph[(df_data_graph[,1]>=vc_x_lim[1])&(df_data_graph[,1]<=vc_x_lim[2]),3]))-0.05, max(c(df_data_org[,"y"],df_data_graph[(df_data_graph[,1]>=vc_x_lim[1])&(df_data_graph[,1]<=vc_x_lim[2]),3]))+0.05) vc_y_lim <- round(vc_y_lim,digits = 1) g <- ggplot(df_data_org,aes(x=x,y=y)) + geom_point() g <- g + geom_line(data = df_data_graph,mapping = aes(x = x, y = y, color = var)) g <- g + xlab(label = "X") + ylab(label = "Y") g <- g + labs(color = "") g <- g + scale_x_continuous(limits = vc_x_lim) g <- g + scale_y_continuous(limits = vc_y_lim) g <- g + theme_classic() + theme(plot.title = element_text(hjust = 0.5),legend.position = "bottom", legend.title=element_text(size = 7), legend.text=element_text(size = 12), legend.background = element_blank()) plot(g)
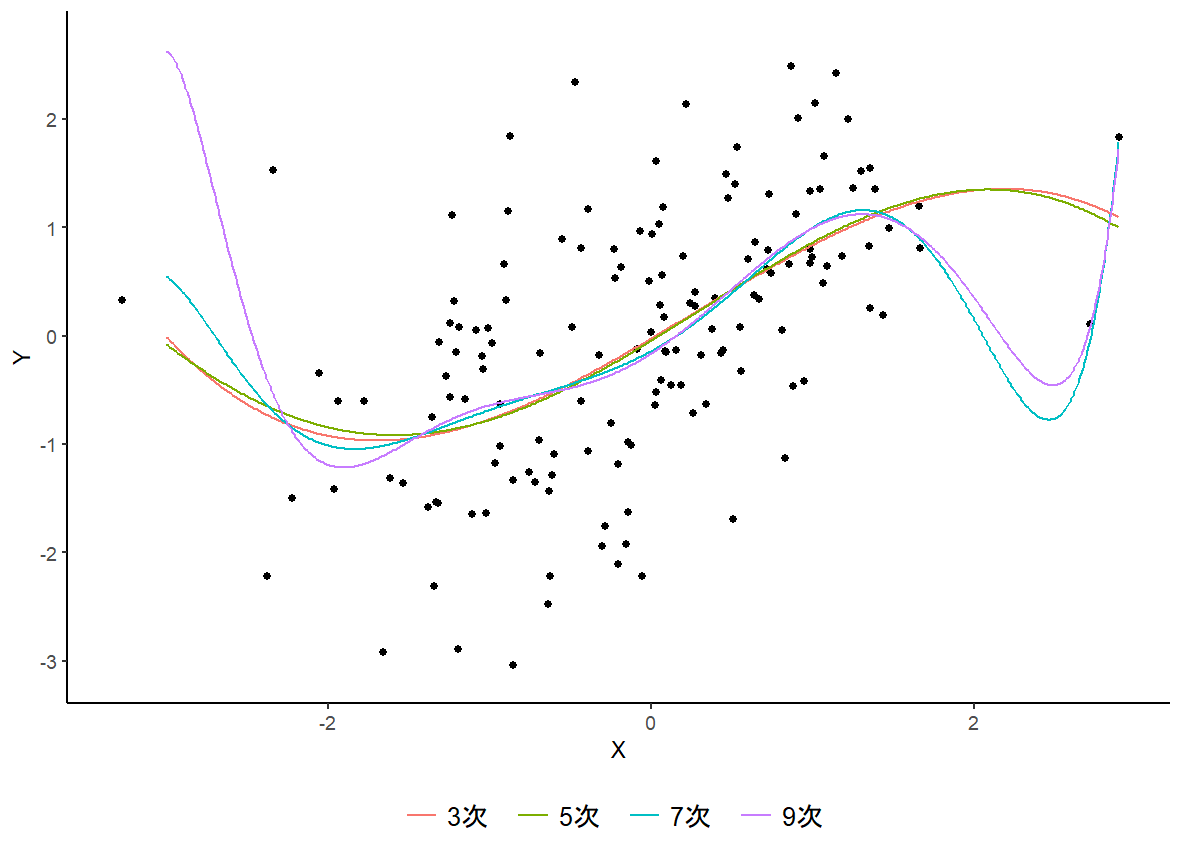 |
################## ### スプライン ### ################## n <- 150 vc_x <- rnorm(n) * 2 * pi vc_y <- sin(vc_x) + 0.2 * rnorm(n) # 区切り点の属性 vc_p_set <- seq(3,9,2) for (k in 1:length(vc_p_set)){ p <- vc_p_set[k] vc_knots <- seq(-2 * pi, 2 * pi, length = p) X <- matrix(nrow = n, ncol = p + 4) for (i in 1:n) { X[i, 1] <- 1 X[i, 2] <- vc_x[i] X[i, 3] <- vc_x[i] ^ 2 X[i, 4] <- vc_x[i] ^ 3 for (j in 1:p){ X[i, j + 4] <- max((vc_x[i] - vc_knots[j]) ^ 3, 0) } } vc_beta <- solve(t(X) %*% X) %*% t(X) %*% vc_y # betaの推定 f <- function(x) { S <- vc_beta[1] + vc_beta[2] * x + vc_beta[3] * x ^ 2 + vc_beta[4] * x ^ 3 for (j in 1:p) S <- S + vc_beta[j + 4] * max((x - vc_knots[j]) ^ 3, 0) return(S) } # 関数fを得る vc_x_seq <- seq(-5, 5, 0.02) if(k==1){ df_spline <- data.frame(x = vc_x_seq, col = paste0("区切り",vc_p_set[k],"個"), y = as.vector(apply(data.frame(vc_x_seq),c(1,2),f))) }else{ df_spline <- rbind(df_spline,data.frame(x = vc_x_seq, col = paste0("区切り",vc_p_set[k],"個"), y = as.vector(apply(data.frame(vc_x_seq),c(1,2),f)))) } } df_test <- data.frame(x = vc_x, col = "テストデータ", y = vc_y) g2 <- ggplot(data = df_test,mapping = aes(x = x, y = y, color = col)) + geom_point() g2 <- g2 + geom_line(data = df_spline,mapping = aes(x = x, y = y, color = col)) g2 <- g2 + xlab(label = "X") + ylab(label = "Y") g2 <- g2 + labs(color = "") g2 <- g2 + scale_color_discrete(breaks = unique(df_spline$col)) g2 <- g2 + scale_x_continuous(limits = vc_x_seq[c(1,length(vc_x_seq))]) g2 <- g2 + theme_classic() + theme(plot.title = element_text(hjust = 0.5),legend.position = "bottom", legend.title=element_text(size = 7), legend.text=element_text(size = 12), legend.background = element_blank()) g2 <- g2 + geom_hline(yintercept = 0, linetype = 3) plot(g2)
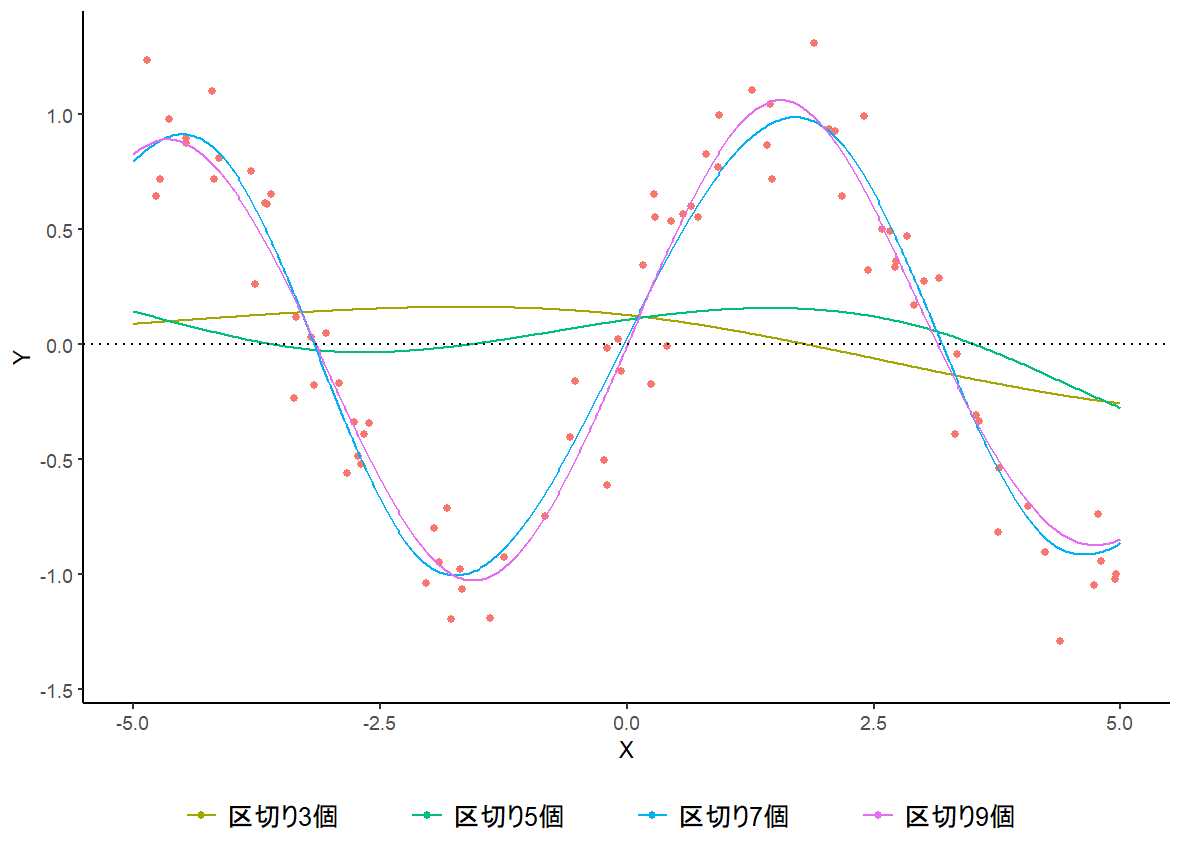 |
6.4.2 Pythonによるシミュレーション例
################## ### 多項式回帰 ### ################## import numpy as np import matplotlib.pyplot as plt %matplotlib inline import japanize_matplotlib import scipy from scipy import stats from numpy.random import randn import copy ########################## ### テストデータの生成 ### ########################## n = 100 x = randn(n) y = np.sin(x) + randn(n) m = 3 p_set = [3,5,7] col_set = ['red','blue','green'] # 多項式の値を計算 def calc_polynomial(beta ,u): S = 0 for j in range(len(beta)): S = S + beta[j] * u ** j return S # グラフ化 plt.scatter(x, y, s = 20, c = 'black') # テストデータの描画 plt.ylim(-3, 3) x_seq = np.arange(-3, 3, 0.1) # 多項式を描画 for i in range(m): p = p_set[i] # 次数の設定 X = np.ones([n,1]) for j in range(1, p + 1): xx = np.array(x**j).reshape((n,1)) X = np.hstack((X,xx)) beta = np.linalg.inv(X.T @ X) @ X.T @ y def polynomial(u): return calc_polynomial(beta, u) plt.plot(x_seq, polynomial(x_seq), c = col_set[i], label = "p={}".format(p)) plt.legend(loc = 'lower left')

###################### ### スプライン回帰 ### ###################### ### テストデータの生成 n = 100 x = randn(n) * 2 * np.pi y = np.sin(x) + randn(n) col_set = ['red','blue','green'] K_set = [5,7,9] plt.scatter(x, y, c = 'black', s = 10) plt.xlim(-5,5) for k in range(len(K_set)): K = K_set[k] knots = np.linspace(-2 * np.pi, 2 * np.pi, K) X = np.zeros((n, K + 4)) # 行列Xの生成 for i in range(n): X[i,0] = 1 X[i,1] = x[i] X[i,2] = x[i] ** 2 X[i,3] = x[i] ** 3 for j in range(K): X[i, j + 4] = np.maximum((x[i] - knots[j])**3,0) beta = np.linalg.inv(X.T @ X) @ X.T @ y def calc_spline(x): S = beta[0] + beta[1] * x + beta[2] * x ** 2 + beta[3] * x ** 3 for j in range(K): S=S+beta[j+4]*np.maximum((x-knots[j])**3,0) return S u_seq = np.arange(-5, 5, 0.02) v_seq = [] for u in u_seq: v_seq.append(calc_spline(u)) plt.plot(u_seq, v_seq, c = col_set[k], label = 'K={}'.format(K)) plt.legend()

*1:実際には4次以上でも問題は無いものの、発散していくことから3次が丁度よい。