Rについて
:データ解析の基礎から最新手法まで")
をベースに学んでいく。
今回は主成分分析(PP.60-73)を扱う。
5. 主成分分析
多くの変数により記述された量的データの変数間にある相関関係を利用し、情報の損失を最小限に抑えつつ、もとの変数の線形結合で表される少数個の無相関な合成変数に縮約して分析する手法を主成分分析という。高次元データをより少数個の変数へ要約して次元圧縮を行い、1次元直線や2次元平面、3次元空間に射影してデータ構造を視覚的に把握するための手法として用いることができる*1。
5.1 主成分導出の過程
一般次元の変数および一般の個数の標本に対する主成分導出の過程を説明しよう。各個体の特徴を捉える個の変数を
とする*2。この
個の変数に関して観測された
個の
次元データ
に基づいて標本分散共分散行列
を計算する。ここでは
次元標本平均ベクトルである。
まず個の変数の線形結合で表される射影軸
上へ個の
次元データを射影して、1次元データ
を得る。これらの平均
は
であるから、その分散
は
で与えられる。したがって射影したデータの分散を最大にするような係数ベクトルは、標本分散共分散行列の最も大きい固有値
に対応する固有ベクトル
として与えられる。この
を係数とする射影軸
が第1主成分である。またその射影軸上での分散は最大固有値
に等しい。
第2主成分は第1主成分と直交するという条件の下で射影した次元データの分散を最大にする軸として与えられ、これは分散共分散行列
の2番目の大きさの固有値
に対応する固有ベクトル
を係数とする射影軸である。更に第3主成分は、第1、第2主成分と直交するという条件の下で射影した
次元データの分散を最大とする軸として定義される。
この過程を順次繰り返すことによって理論上、もとの変数の線形結合で表される個の主成分が導出される。以上の過程から明らかなように、主成分分析は標本分散共分散行列の固有値問題に帰着できる。
5.2 標本分散共分散行列の固有値問題と主成分
観測された個の
次元データに基づく標本分散共分散行列を
とする。標本分散共分散行列は
次元対称行列である。そこで
の固有方程式
の解として与えられる
個の固有値を
とする。また各固有値に対応する、長さがになるように規格化した
次元固有ベクトルをそれぞれ
とおく。これらの固有ベクトルは規格化と直交化、すなわち
が成り立っていることを注意しておく。
このときもとの変数の線形結合で表される個の主成分とその分散は
で与えられる。
主成分分析を適用することで、もとの個の変数について観測された
個の
次元データ
を
次元へと縮約できる。高次元データを1次元直線、2次元平面または3次元空間へと射影してデータ構造を視覚的に把握するとともに、元の変数の線形結合として合成された新たな変数のもつ意味を見出すことによって有益な情報抽出が可能になる。
合成された主成分の持つ意味は、各変数の係数の大きさや政府を通して把握できる。他方で定量的な指標として主成分と各変数の相関を求めておけば、主成分に影響する変数を特定するのに有用である。
一般に第主成分
と第
番目の変数
との間の相関は
で与えられる。ここでは第
主成分の分散、
は第
主成分を構成する変数
の係数、
は変数
の分散である。
5.3 対称行列の固有値と固有ベクトル
標本分散共分散行列
は次対称行列で、その固有値および固有ベクトルの間には以下が成り立つ:
いま個の固有ベクトルを列ベクトルとする
行列を
、固有値を対角成分に持つ
対角行列を
とする。すなわち
とする。このとき標本分散共分散行列の固有値と固有ベクトルの関係は
である。(2)式は対称行列は直交行列
によって対角化可能であることを示しており、(3)式は対称行列
のスペクトル分解と呼ばれている。また(4)式はもとの変数
の分散の総和
が新たに構成した
個の主成分の分散の総和
に等しいことを表す。
5.4 多次元データの基準化と標本相関係数
観測された個の
次元データを
とするとき、個の
次元データに基づく標本平均ベクトル
と標本分散共分散行列
を求める。次に上式の第
番目の
次元データを
により規格化する。このように規格化された個の
次元データに基づいて標本分散
と標本共分散
を計算すると、
である。したがって規格化したデータに基づく標本分散共分散行列は、対角成分がすべて
で、非対角成分
が
番目と
番目の変数間の標本相関係数からなる
次正方行列
に等しく、これを標本相関行列という。
規格化した多次元データから出発する主成分分析は標本相関行列の固有値問題に帰着され、主成分を導出する過程は標本分散共分散行列から出発する場合と同様である。
5.5 次元圧縮と情報損失
主成分を用いて高次元空間に散らばるデータの次元を我々の直感で捉えることができる1次元直線、2次元平面または3次元空間へと圧縮することにより、視覚的に高次元データ構造を捉えることができる。ただし高次元データを低次元の空間へと圧縮すると情報の損失が生じることから、次元圧縮による情報損失を定量的に把握しておく必要がある。
情報損失の例を述べる。2科目の試験においてというデータを
軸へ射影することで圧縮するとどちらも
となるため、区別が出来なくなる。この損失をできるだけ少なくするために射影したデータが最も散らばる軸を探していると言える。
主成分分析は情報の量を分散で捉えているため、求めた主成分の分散の相対的な大きさを見れば情報の損失を定量的に把握できる。すでに示したように第主成分の分散
と対応する固有値で表されたから、もとの
個の変数
のもつ情報の中で、第
主成分
にはどの程度の情報が含まれている情報の量を測るための基準は、
で与えられ、寄与率という。また第主成分から第
主成分までを用いたときの情報の量は
で与えられ、累積寄与率という。
固有ベクトルを列ベクトルとするおよび固有値を対角成分にもつ
、すなわち
に対して
が得られるから、もとの変数のもつ全情報(=各変数の分散の総和
)は
個の主成分
の全情報
へと受け継がれるが、次元圧縮により一部の主成分を用いたときには情報の損失が生じる。そのために用いる主成分にどの程度の情報が含まれているかを定量に測るために、全主成分の分散の総和に対する各主成分の分散の相対的な割合を情報損失の基準としていると言える。
5.6 Rによる分析結果
データとしてを用いて主成分分析を行ってみる。
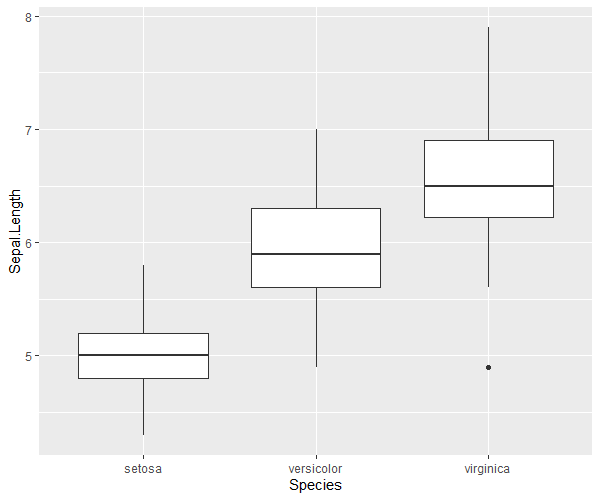
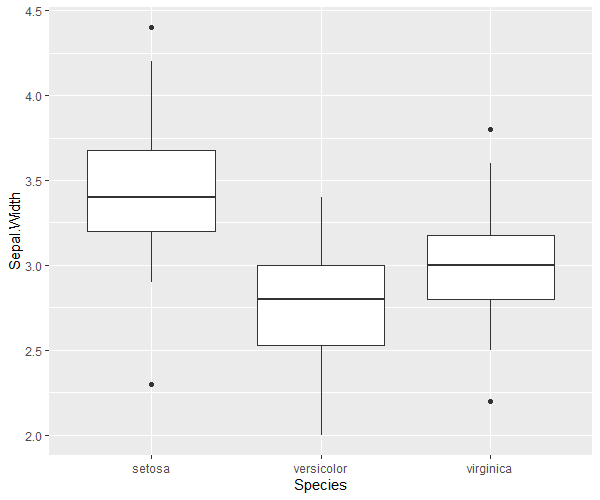
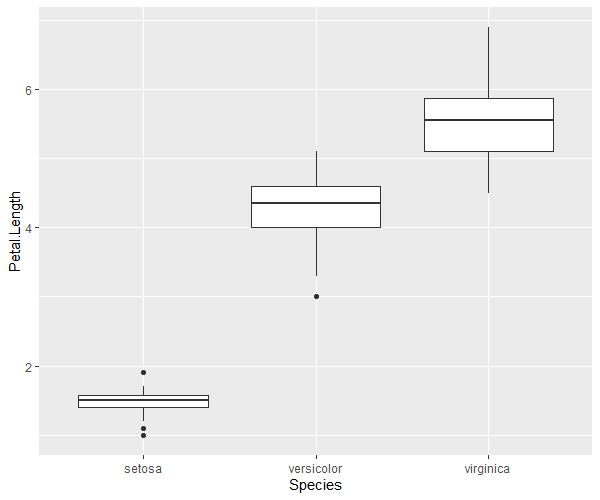
サンプルデータの分布
 |
 |
 |
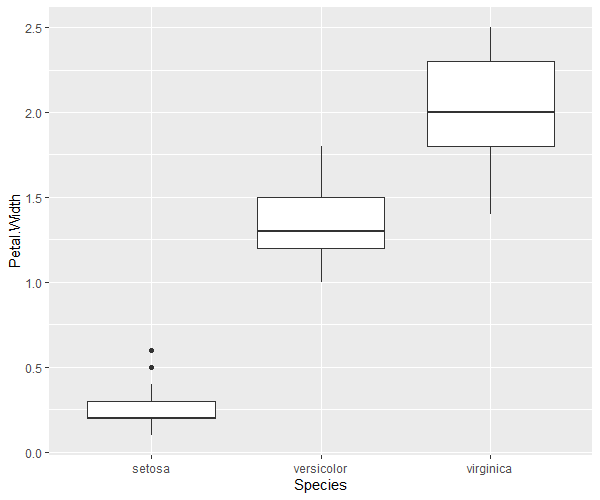 |
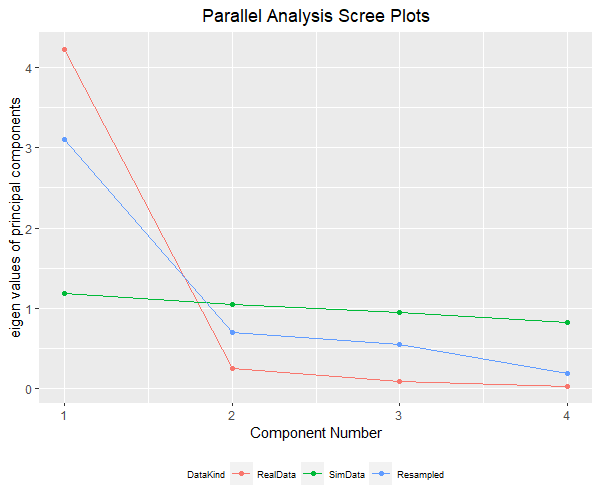
# library(stats) # statsは読込不要 # サンプルデータはiris data(iris) # まずはサンプルデータの概形を分析 library(ggplot2) library(ggrepel) # Speciesごとに統計量を算出 for(species in unique(iris[,"Species"])){ print(summary(iris[iris[,"Species"]==species,])) } # 列ごとに図示 ggplot(iris,aes(x = Species, y = Sepal.Length)) + geom_boxplot() ggplot(iris,aes(x = Species, y = Sepal.Width)) + geom_boxplot() ggplot(iris,aes(x = Species, y = Petal.Length)) + geom_boxplot() ggplot(iris,aes(x = Species, y = Petal.Width)) + geom_boxplot() # 主成分分析を実施 ls_comp <- princomp(iris[,-5], cor = F, scores = T) ls_comp$sdev # 標準偏差 ls_comp$loadings # 固有ベクトル:空欄は近似的に0 ls_comp$center # 平均 ls_comp$scale # 各変数に適用されたスケール ls_comp$n.obs # 観測値のサイズ ls_comp$scores # 主成分データの得点 summary(ls_comp) # 寄与率・累積寄与率 # 第1成分だけで9割近くの寄与度があるため、第1・第2成分のみで主成分を表示 summary(ls_comp) # 寄与率・累積寄与率 df_prin_comp <- data.frame(names = row.names(ls_comp$loadings),ls_comp$loadings[,c(1,2)]) row.names(df_prin_comp) <- NULL g <- ggplot(df_prin_comp,aes(x = Comp.1,y = Comp.2, label = names)) + geom_point() g <- g + geom_label_repel()+ theme(plot.title = element_text(hjust = 0.5),legend.position = "bottom", legend.title=element_text(size = 7), legend.text=element_text(size = 7)) plot(g) # 主成分得点 # 情報を縮約した結果であり、元の変数・個体間の相対的関係に過ぎない df_prin_comp_2 <- data.frame(labels = iris[,5],ls_comp$scores) g_pcs <- ggplot(data = df_prin_comp_2, aes(x = Comp.1, y = Comp.2, colour = labels)) + geom_point() g_pcs <- g_pcs + theme(plot.title = element_text(hjust = 0.5),legend.position = "bottom", legend.title=element_text(size = 7), legend.text=element_text(size = 7)) plot(g_pcs) # 主成分の数を判定する:ここでは平行分析法 library(psych) lst_pc_num <- fa.parallel(x = iris[,-5], fa = "pc", cor = "cov", n.iter = 1000, error.bars = F) # 結果を図示 df_parallell_analysis <- data.frame("NumComp" = 1:length(lst_pc_num$pc.values), "DataKind" = rep("RealData",length(lst_pc_num$pc.values)), "Data" = lst_pc_num$pc.values) df_parallell_analysis <- rbind(df_parallell_analysis, data.frame("NumComp" = 1:length(lst_pc_num$pc.sim), "DataKind" = rep("SimData",length(lst_pc_num$pc.sim)), "Data" = lst_pc_num$pc.sim)) df_parallell_analysis <- rbind(df_parallell_analysis, data.frame("NumComp" = 1:length(lst_pc_num$pc.simr), "DataKind" = rep("Resampled",length(lst_pc_num$pc.simr)), "Data" = lst_pc_num$pc.simr)) g_pa <- ggplot(data = df_parallell_analysis,aes(x = NumComp, y = Data, colour = DataKind)) + geom_line() g_pa <- g_pa + ggtitle("Parallel Analysis Scree Plots") + xlab("Component Number") + ylab("eigen values of principal components") g_pa <- g_pa + geom_point() + theme(plot.title = element_text(hjust = 0.5),legend.position = "bottom", legend.title=element_text(size = 7), legend.text=element_text(size = 7)) plot(g_pa) # 予測:全データの一部を学習データ、残りをテストデータとして予測する # 学習データの行番号 vc_resampling <- sample(x = 1:nrow(iris),size = as.integer(round(0.5 * nrow(iris))),replace = F) ls_comp <- princomp(iris[vc_resampling,-5], cor = F, scores = T) # 学習データでの主成分分析 # テストデータで予測 pred_comp <- predict(object = ls_comp, data = iris[-vc_resampling,-5]) pred_comp
主成分(第1成分と第2成分)の散布図

主成分得点の散布図(第1成分と第2成分)